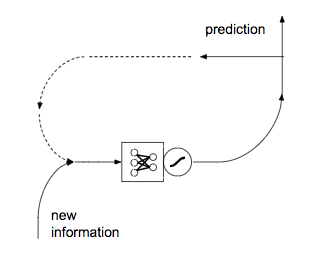
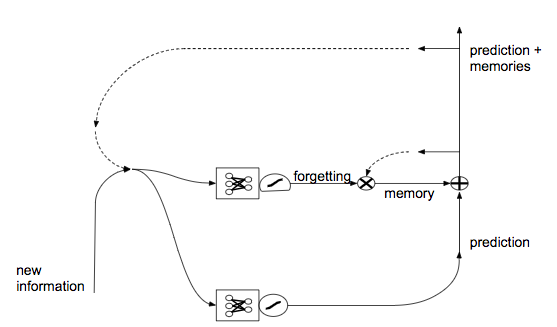
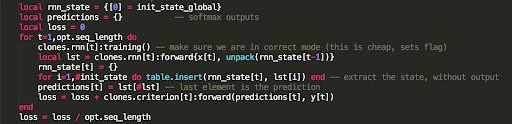
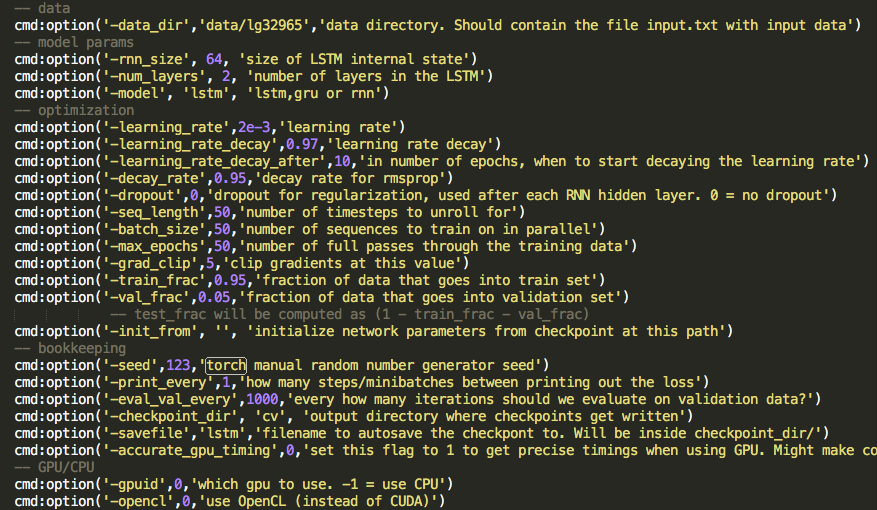
Evaluation
Results
We achieved exciting and entertaining results using the character-RNN discussed above. As we were originally motivated by our excitement for food, we quite enjoyed the sample results we generated using this model.
In terms of evaluation, our main concern was the grammatical correctness of our generated recipes. Given that this was our primary concern, our recipes were not always functionally coherent. For example, in a given generated ingredient list, most of the words will not be misspelled. In addition, the units of measurement usually match up to the type of ingredient they are describing. However, the ingredients listed won't sound like a good combination to a human, and likely won't even include the ingredients mentioned in the title of the recipe. That being said, the grammatical correctness of our generated recipes produced entertaining results which can be found in more detail below.
LSTM
In terms of overall coherency and least amount of misspellings, our best results came from training with an LSTM. As mentioned earlier, we trained on some sets of data that just included ingredients, and some that included both ingredients and instructions. Our most coherent and entertaining samples were those that included just ingredients, as it was quite difficult to produce coherent directions. A sample of both can be seen below, with the first including just ingredients, and the second with ingredients and directions.
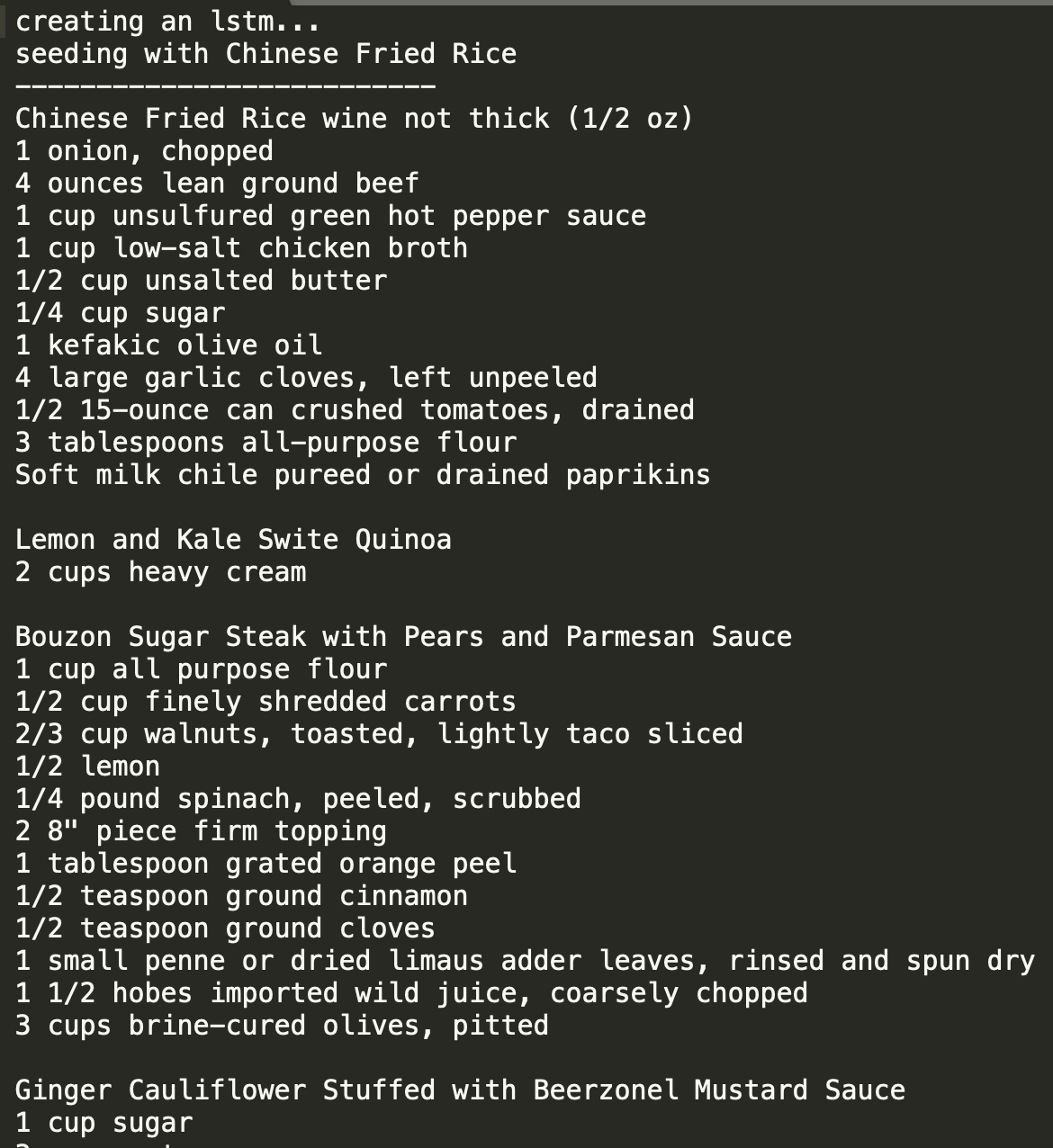
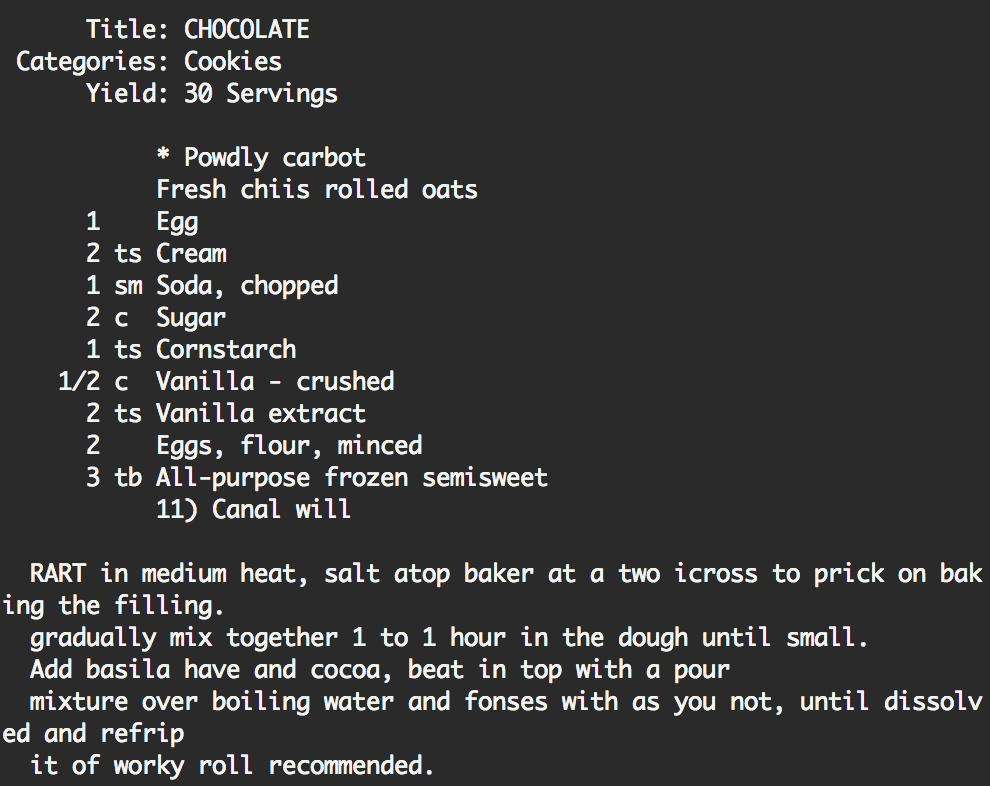
RNN
We achieved similar results as above when using a simple RNN. This was a bit surprising to us both, as we thought the LSTM would be significantly better, given its usefulness when training on natural language. As seen below, training with a simple RNN was also able to produce interesting ingredients and directions.
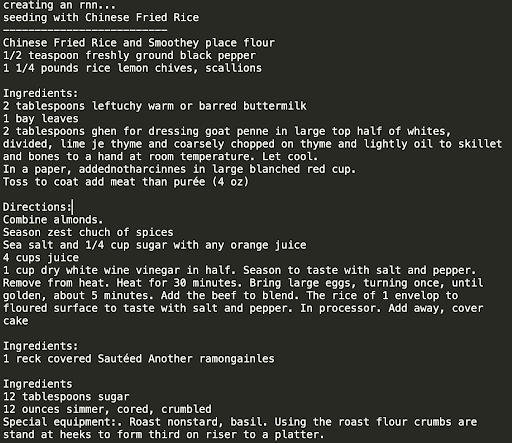
GRU
After training with the LSTM, we also trained a GRU on our data. Although similar runtime as the training for the LSTM, the results were significantly less coherent. While we could consistently produce ingredients without misspelled words with the LSTM, that was not the case with the GRU. As seen below, neither the ingredients nor directions generated by the GRU are grammatically correct English.
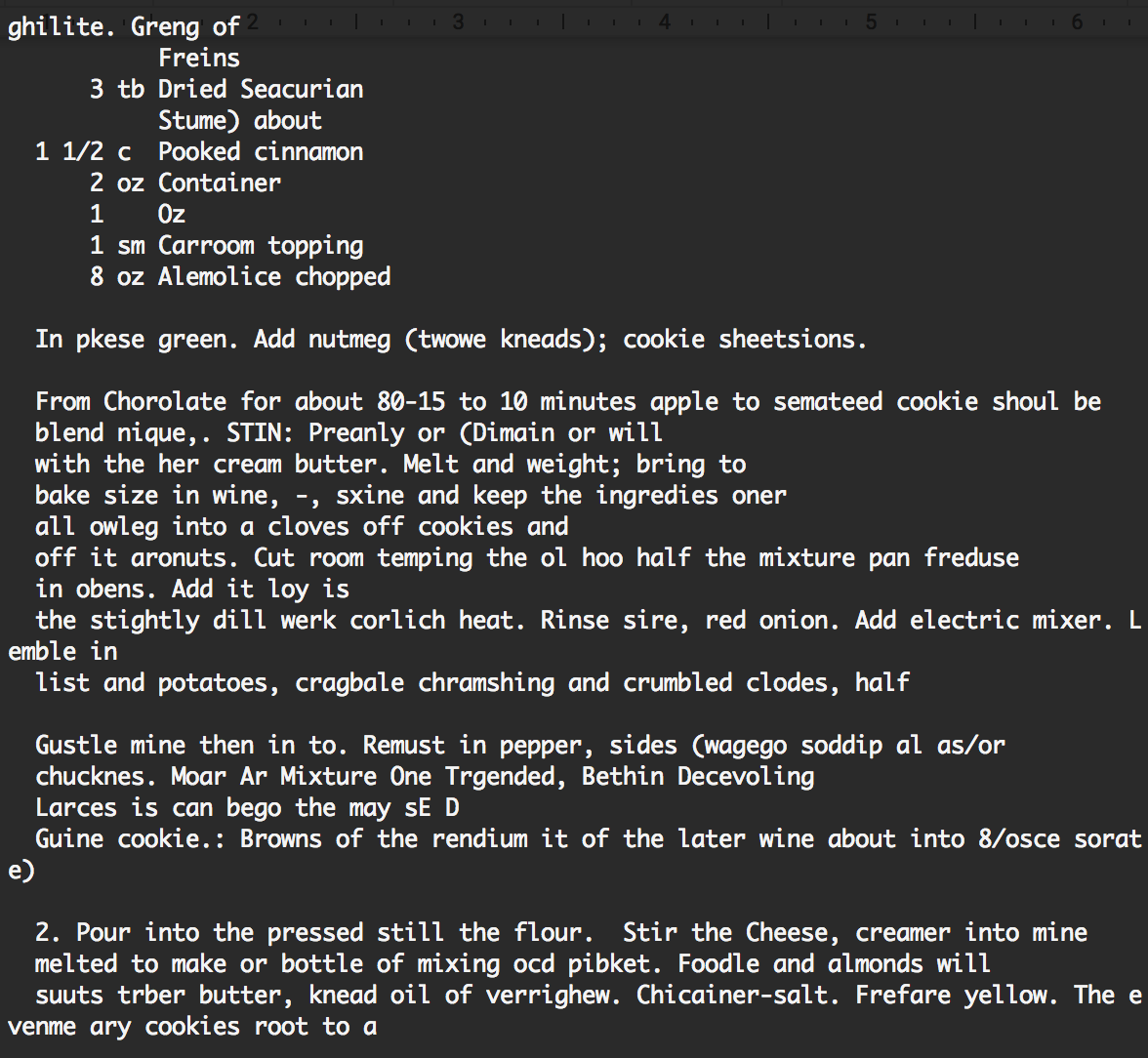
Word-RNN
As mentioned above, we initially experimented with using a Word-RNN rather than a character RNN. We were concerned with the misspellings we were getting using the character-RNN, which is why we chose to look into using a Word-RNN. Because the Word-RNN doesn't break up words, we would not have any misspellings, but would trade that for overall coherency. We quickly found that the Word-RNN wasn't the right direction for us to go, as it produced a truly random sample of words, as seen below.
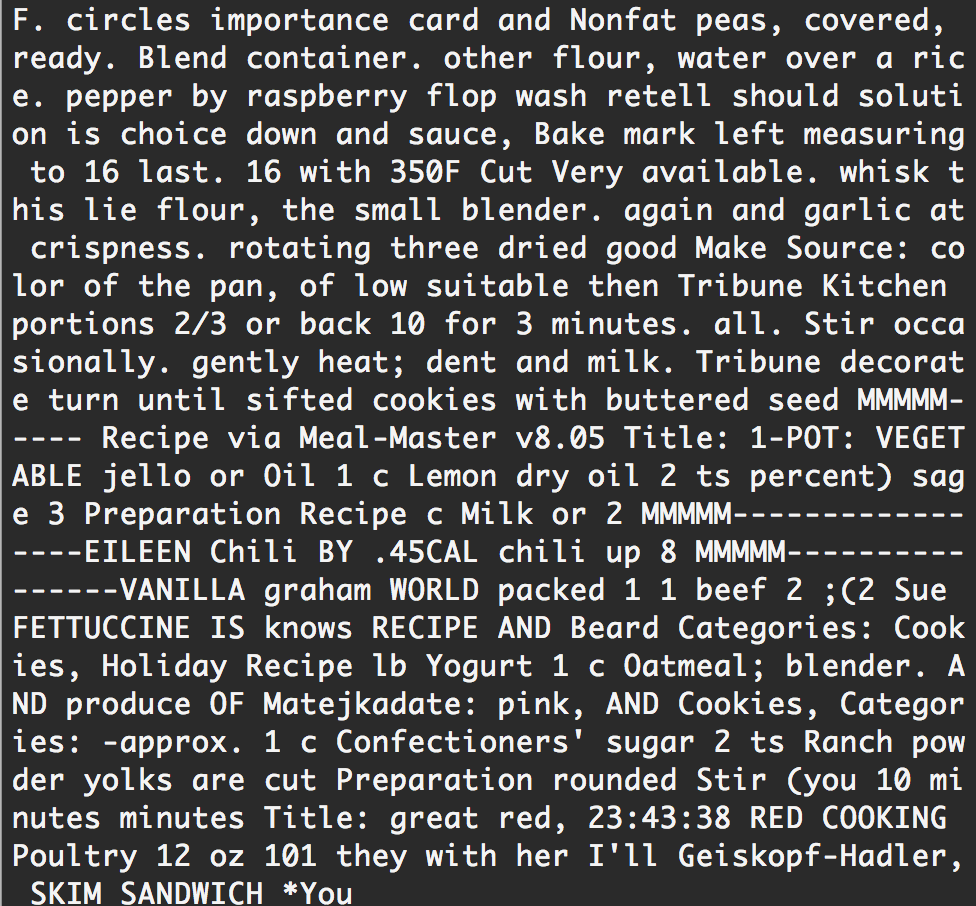
Future Work
In the future, if given the opportunity and time, we would like to see what interesting results our model could output if we trained it on other various aspects of recipes including the nutrition facts, cuisine type, rating, and more. We would like to experiment on how well a GANs model would perform to generate new recipes. In addition, either through more training, different parameters to our model, or pruning our results, we would like to see how we could increase our recipe accuracy and have our recipe actually correlate with ingredients. It'd be interesting to see if we could create realistic recipes to try in the kitchen.
What We've Learned
The two of us learned new things at every step in the process of building our model. During the data collection stage, we both learned how to find and handle large sets of data, and how to understand if the data fits the project needs and requirements. After finding the data, we had to learn how to preprocess it, and adjust it for the requirements of our project. Once we bagan training the model, we learned how to adjust the parameters of a neural net, and gain an understanding of how each parameter functionally affects the model. By getting to quickly see the results on our data achieved by adjusting parameters such as network size, number of layers, and seed text, we were able to make generalizations that allowed us to understand recurrent networks better as a whole.